RAG vs Memory: Addressing Token Crisis in Agentic Tasks
Context windows grew 20x. Token consumption grew faster. Here’s why RAG alone isn’t enough and what memory-based approaches offer.
The problem: Agentic tasks eat tokens for breakfast
Remember when 8K tokens was our bottleneck in 2023? We begged for bigger context windows. Now we have 200K with Claude 4, even 1M with Gemini 2.5.
Problem solved? Not even close.
Turns out, the tasks we’re running now consume tokens way faster than we expected. It’s not about simple queries anymore. We’re building agents that code, research, and browse the web autonomously. These aren’t one-shot tasks. They’re long-running, iterative processes.
Let’s look at what’s actually happening.
Coding agents like Cursor and Windsurf burn through context in a single session:
- Current files: 10-50K tokens
- Chat history: 5-20K tokens
- Edit logs: 10-50K tokens
- Project context: 20-100K tokens
Total? 50-200K tokens. You can’t sustain 30 minutes of intensive coding without hitting the wall and losing continuity.
Deep research agents are even hungrier. OpenAI’s Deep Research consumes over 2M tokens per query, generating 7-48 page reports with hundreds of sources.
Web search agents accumulate context with every iteration. Search → Read → Assess → Search again → Read more. After 10-15 steps, you’ve maxed out even the largest context windows.
This creates two problems:
Cost: A 2M token research query costs $30+ in API fees. Building a product that runs hundreds of queries daily? That’s thousands in costs.
Capability: When agents hit context limits mid-task, they lose everything. Imagine debugging for 25 minutes, making real progress, then the agent forgets and you restart.
Token efficiency directly impacts your bottom line and this calls the need for better memory management
RAG: The standard approach
Most systems today use RAG (Retrieval-Augmented Generation). Store data externally, retrieve relevant chunks when needed, generate responses.
| Strengths | Limitations |
|---|---|
| Simple to implement | One retrieval attempt only |
| Fast for straightforward queries | Performance capped by embedding quality |
| Works when first retrieval succeeds | Stuck if initial search misses |
| Proven at scale | No way to refine or iterate |
| Can’t do multi-hop reasoning |
Think of RAG like ordering delivery. You place one order, whatever shows up is what you get. If you forgot something, too bad.
Memory-based approach: How MemGPT works
This is where hierarchical memory comes in. Instead of one retrieval attempt, treat the LLM like a computer with RAM and disk storage.
Your main context (200K tokens) is like RAM (fast, expensive, limited). External storage is like your hard drive (slow, cheap, unlimited). The LLM actively manages what stays in RAM versus what gets stored on disk.
Here’s the architecture:
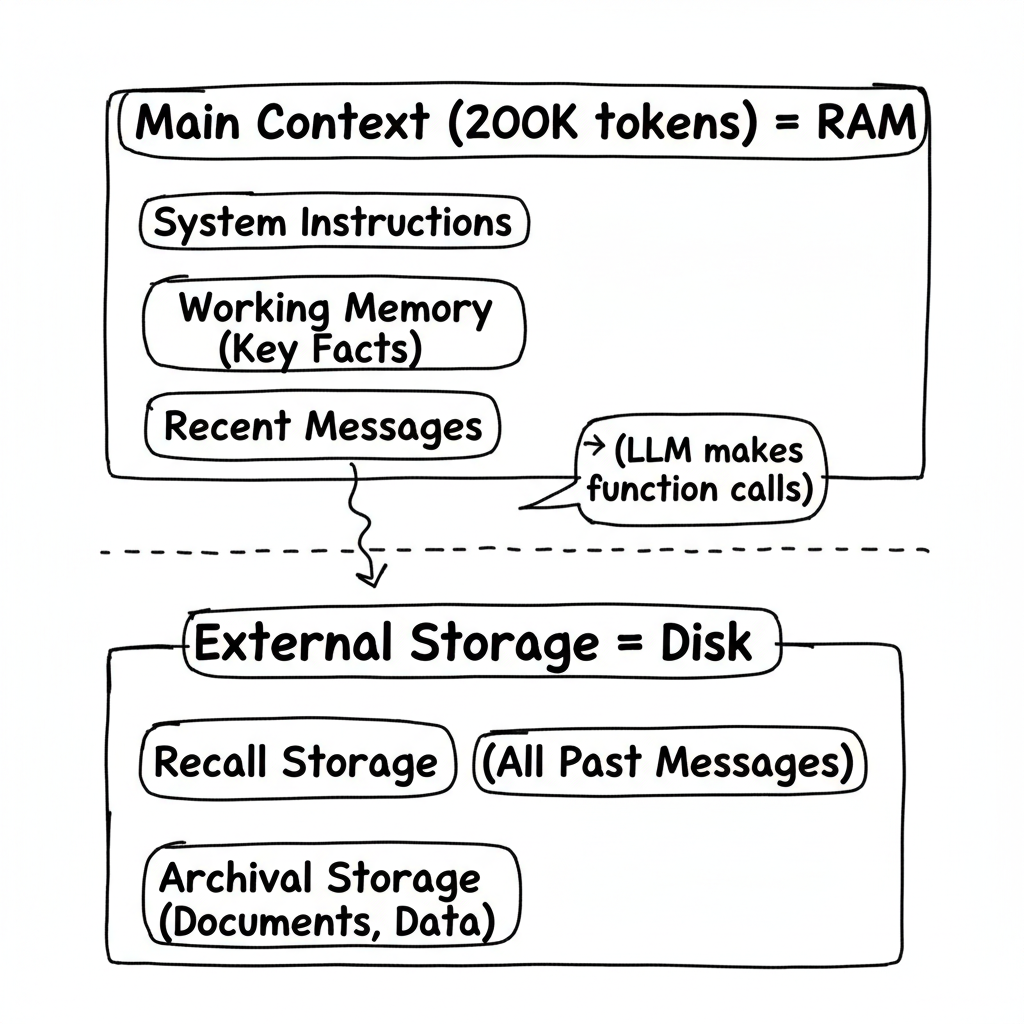
How it manages memory:
- Context hits 70% full → LLM gets a memory pressure warning
- LLM decides what’s important and writes it to permanent storage
- Context hits 100% → Old messages automatically flush to recall storage
- Need something from the past? → LLM searches and retrieves it
The key difference: The LLM controls the retrieval loop. Not a fixed pipeline.
This means:
- Multiple retrieval attempts
- Can refine queries based on results
- Can page through search results
- Handles multi-hop reasoning
Think of this like cooking with a stocked kitchen. You keep going back for ingredients until the dish is done.
Head-to-head: Performance comparison
Let’s look at how these approaches perform on different tasks, using data from the MemGPT paper.
Document Q&A: When your first search misses
Scenario: Answer questions from 200+ Wikipedia documents. The right document isn’t in your top-k retrieval results.
| Approach | Accuracy |
|---|---|
| RAG (fixed-context) | <50% |
| Memory-based | ~65% |
Why memory wins: Can make multiple retrieval calls, refine queries, page through results. Not stuck with one search.
Multi-hop reasoning: Chaining lookups
Scenario: Need to chain 4 lookups where each answer becomes the next question. All 140 key-value pairs are visible in context.
Example: START → WIZARD → OLD_MAN → CASTLE → TREASURE
| Approach | Accuracy at 3+ hops |
|---|---|
| GPT-4 (all data in context) | 0% |
| RAG | 0% |
| Memory-based | 100% |
Why memory wins: Makes discrete, focused queries one at a time. Even with all data visible, focused beats overwhelmed.
Long conversations: Deep memory retrieval
Scenario: Remember specific details from conversations weeks ago.
| Approach | Accuracy |
|---|---|
| Fixed-context | 32% |
| Memory-based | 92% |
Why memory wins: Searches past messages on-demand instead of trying to fit everything in context.
When to use what
Here’s my decision framework based on building with both approaches.
| Scenario | RAG | Memory-Based |
|---|---|---|
| Task duration | Short, one-off queries | Long-running sessions (30+ min) |
| Reasoning type | Single-hop, direct answers | Multi-hop, iterative refinement |
| Use cases | Simple Q&A, document lookup | Coding agents, deep research, web search agents |
The reality: Most production systems use both. RAG for simple queries, memory management for complex tasks. It’s not either/or.
Other approaches worth mentioning
Beyond RAG and memory, two other techniques help:
Summarization: Periodically compress conversation history. Simple to implement but loses details. Good for extending conversations when exact recall isn’t needed.
Context optimization: Intelligently pack only what’s necessary. Remove redundancy, compress code, semantic search for relevance. Works as a complement to other approaches.
These don’t solve the fundamental scaling problem, but they help.
The bottom line
Context windows grew 20x (from 8K to 200K and beyond). But agentic tasks grew faster. Coding sessions routinely hit 50-200K tokens. Research queries can exceed 2M tokens.
RAG works great when one retrieval finds the answer. It’s fast, simple, and proven. But it breaks down for multi-hop reasoning and long-running tasks. One-shot retrieval is the bottleneck.
Memory-based approaches flip the script. Instead of retrieve-once-and-hope, the LLM manages what stays in context and what gets stored externally. Multiple retrieval attempts. Iterative refinement.
The performance gap is clear:
- Multi-hop tasks: 100% vs 0%
- Long conversations: 92% vs 32%
- Large document sets: 65% vs <50%
Key takeaways:
- Use RAG for: Simple queries, speed-critical tasks
- Use memory for: Long-running agents, multi-step reasoning, complex research
- Most production systems need both